What is a Data Warehouse?
It helps to contrast the Data Warehouse to something you already know. So, let’s compare to a traditional Database.
Database (DB) VS Data Warehouse (DW)
Forgive me for somehow simplifying and not accounting for the diversity out there, but I’ll sum this up to the following:
Databases are used for OnLine Transaction Processing
(OLTP); that is for transactions that historically aim to optimize the support of daily business operations (transactions), while ensuringconcurrent accessanddata consistencythrough ACID (for NoSQL maybe forget that last part).Data Warehouses are used for OnLine Analytical Processing
(OLAP); that is for accessing, analyzing and exploiting data that is oriented towards gaining insights. Typically, a Data Warehouse will be loaded with historical data from different sources throughExtract-Transform-Load(ETL) operations. Under the hood, data warehouses use databases. While, there are potentially many DBs in an enterprise, there will be only one DW.
In just one sentence: with Databases we store and update, with Data Warehouses we analyze. Each one is tuned for its use-case.
DW queries
While DBs are made to answer ad-hoc queries, Data Warehouses are built for spreadsheet-like analytical queries. They can answer rapidly queries like how many products have been bought per day, month, year, shop or any dimension of the facts present in the DW.
The SQL of relational DW is called MDX and is meant to query the Data Cubes that comprise the DW.
Typical operations in OLAP queries are:
Dice: Filters the data cube.
Drill down/up: Allows to navigate zoom in/out in the data cube (e.g. navigate from
per-month(up) $\rightarrow$per-day(down)).Rollup: aggregates data accross a dimension of the cube.
DW Architectures
1. Traditional architecture (Centralized DW)
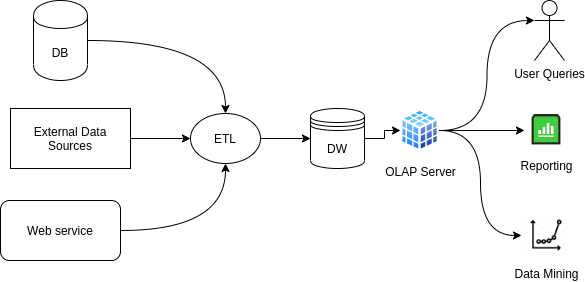
Figure: Traditional DW Architecture. Created in draw.io
This is the traditional architecture where multiple data sources are loaded into the data warehouse through ETL and then served to the various users (e.g. reporting, data mining, user queries) through an OLAP server.
2. With a Data Lake
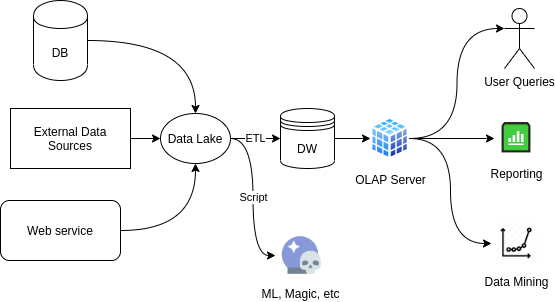
Figure: Data Lake Architecture. Created in draw.io
A data lake’s all the data of an organization in a loosely structured way. It is commonly implemented with HDFS.
Then, a DW or Data Marts (let’s say mini DWs) can be extracted. The Data Lake can provide a single source of data for the DW and also be available for other direct uses, like creating Machine Learning models.
3. Other
There’s an interesting study by Watson and Ariyachandra comparing different DW architectures.
DW-specific Optimizations
Let’s now see what DW do differently from traditional OLTP systems.
1. Denormalization
DW tables can be higly denormalized for read performance without joins.

Figure: Denormalization. Source
2. Pre-computed cubes
Aggregated cross-tabulations are very useful for analysis
| Sales | Q1 | Q2 | Q3 | Q4 | Total |
|---|---|---|---|---|---|
| Product1 | 1 | 4 | 4 | 3 | 12 |
| Product2 | 2 | 3 | 10 | 2 | 17 |
| Product3 | 3 | 3 | 11 | 1 | 18 |
| Total | 6 | 10 | 25 | 6 | 47 |
Since, you may know what types of queries to expect in a DW, it is common practice to pre-compute data cubes. Data has multiple dimensions and you don’t want to materialize the whole hypercube (see curse of dimensionality)
Compared to searching in traditional database tables, searching in the data cube, requires multidimensional indexes as the ones also used in spatial databases.
3. No ACID
In general, OLAP systems do not need to support ACID and therefore relax some of its properties. They can be faster this way.