Spam Classification with Spark MLLib
Disclaimer: This blog post will present my solution to an exercise of the Scalable Data Science offered by TU Berlin in winter semester 2019-2020.
Introduction
In this exercise, we had to learn a model to classify spam, nospam SMS messages. We were given the SMS Spam Collection Data Set, split in 4 files:
training_spam.txttraining_nospam.txttesting_spam.txttesting_spam.txt
The goal is to train a model on the contents of the training* files and use it to predict the testing*.
For this, we will use Spark MlLib, which is the Machine Learning library, built on top of Apache Spark.
Let’s dive into the solution.
Data Loading
// load data as spark-datasets
val spam_training = spark
.read.textFile("./path/spam_training.txt")
val spam_testing = spark
.read.textFile("./path/spam_testing.txt")
val nospam_training = spark
.read.text("./path/nospam_training.txt")
val nospam_testing = spark
.read.text("./path/nospam_testing.txt")
Dataset imbalance
println("Spam training count: " + spam_training.count())
println("No Spam training count: " + nospam_training.count())
println("Spam testing count: " + spam_testing.count())
println("No Spam testing count: " + nospam_testing.count())
We get the following output:
Spam training count: 598
No Spam training count: 3862
Spam testing count: 149
No Spam testing count: 965
The dataset is very imbalanced. Therefore, accuracy will not be a good measure to measure to evaluate our algorithm. Naively predicting everything as non-spam would get us an accuracy of $\frac{965}{965+149}\approx0.866$.
Instead, we will use the $f_{1}$ score.
Pipeline
After loading our data, we want to create our pipeline. The main idea is that spam sms contain a different distribution of both words and symbols. Thus, we construct a pipeline to create a bag-of-words and a bag-of-symbols that we weight using the TF-IDF algorithm. Then, we will use a Linear SVM to classify. The vocabulary sizes of the bags and the maximum iteration hyper-parameter of the Linear SVM will be chosen via cross-validation in the training set (train_df), based on the f1-score. Then, we will predict in the testing set (test_df) and print the accuracy, f1-score and confusion matrix that our best model achieves in both training and testing. The implementation of the above pipeline follows.
Step 1. Tokenize symbols
First, we create the tokenizer for the symbols (non alphabetic characters). Symbols are very important when it comes to spam messages.
val symbolTokenizer = new RegexTokenizer()
.setInputCol("text")
.setOutputCol("symbols")
.setPattern("[a-zA-Z\\ ]*")
Step 2. Tokenize words
Similarly, we create the tokenizer for the words.
val wordTokenizer = new RegexTokenizer()
.setInputCol("text")
.setOutputCol("words")
.setPattern("[^A-Za-z]")
Step 3. Remove stopwords
Then, we create the stop word remover that will remove common english words like “the, a, …”:
val remover = new StopWordsRemover()
.setInputCol("words")
.setOutputCol("filtered_words")
Step 4. Bag-of-words
Then, we create the bag-of-words and bag-of-symbols:
val bow_symbols = new CountVectorizer()
.setInputCol("symbols")
.setOutputCol("raw_symbol_features")
val bow_words = new CountVectorizer()
.setInputCol("filtered_words")
.setOutputCol("raw_word_features")
Step 5. TF-IDF
We weigh them using the TF-IDF method as provided by the spark.ml api:
val idf_symbols = new IDF()
.setInputCol("raw_symbol_features")
.setOutputCol("symbol_features")
val idf_words = new IDF()
.setInputCol("raw_word_features")
.setOutputCol("word_features")
Step 6. Label encoding
We encode the label categories (“spam”, “nospam”) to (0, 1), to the label column as input to our model.
val si = new StringIndexer()
.setInputCol("label_category")
.setOutputCol("label")
Step 7. Feature Assembly
We assemble our features (symbol features, word features) in one vector:
val assembler = new VectorAssembler()
.setInputCols(Array("symbol_features", "word_features"))
.setOutputCol("features")
Step 8. Classifier
We define a Linear SVM as our model for classification.
val svm = new LinearSVC()
Step 9. Assemble pipeline
Last but not least, we specify the above steps as the stages of our ML pipeline
val pipeline = new Pipeline()
.setStages(Array(
symbolTokenizer, // tokenize symbols
wordTokenizer, // tokenize words
remover, // remove stopwords
bow_symbols, // bag-of-words
bow_words, // bag-of-symbols
idf_symbols, // tf-idf for bag-of-symbols
idf_words, // tf-idf for bag-of-words
assembler, // assemble features in one vector
si, // encode label category
svm // svm classifier
))
Cross Validation
There are some hyper-parameters of our model that we need to tune:
- Vocabulary size of the bag-of-words
- Vocabulary size of the bag-of-symbols
- Max iterations for the SVM model
There are of course other parameters that we could also tune, which could be more meaningful but want to avoid a very slow training and just have this here to showcase how to use cross-validation for evaluation in MlLib.
To avoid overfitting to our testing set, we perform 5-fold cross validation in the training in order to tune these parameters. As discussed earlier, for such an imbalanced dataset, $f_{1} score$ is a better metric to optimize than accuracy. Therefore we perform the cross validation, using $f_{1} score$ for the evaluation of each model.
val multiEvaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setMetricName("f1")
.setPredictionCol("prediction")
// We use a ParamGridBuilder to
// construct a grid of parameters to search over.
// With 2 values for each CountVectorizer.vocabSize
// and 2 values for svm.maxIter,
// this grid will have 2 x 2 x 2 = 8 parameter
// settings for CrossValidator to choose from.
val paramGrid = new ParamGridBuilder()
.addGrid(bow_symbols.vocabSize, Array(1000, 2000))
.addGrid(bow_words.vocabSize, Array(1000, 2000))
.addGrid(svm.maxIter, Array(10, 20))
.build()
// We now treat the Pipeline as an Estimator,
// wrapping it in a CrossValidator instance.
// This will allow us to choose
// parameters for all Pipeline stages.
// A CrossValidator requires an Estimator,
// a set of Estimator ParamMaps, and an Evaluator.
// We choose to optimize f1-score and
// thus use the MulticlassClassificationEvaluator
// that supports the metric
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(multiEvaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(5)
.setSeed(42) // set a seed for reproducible results
// Run cross-validation,
// and choose the best set of parameters.
val cvModel = cv.fit(train_df)
Evaluation
To evaluate our model, we will print the accuracy, the $f_{1} score$ and the confusion matrix both in training and testing sets.
val predictionsTrain = cvModel.transform(train_df)
val predictionsTest = cvModel.transform(test_df)
val predictionAndLabelsTrain = predictionsTrain
.select("prediction", "label")
.rdd.map(row => (row.getDouble(0),row.getDouble(1)))
val predictionAndLabelsTest = predictionsTest
.select("prediction", "label")
.rdd.map(row => (row.getDouble(0),row.getDouble(1)))
val multiMetricsTrain = new MulticlassMetrics(predictionAndLabelsTrain)
val multiMetricsTest = new MulticlassMetrics(predictionAndLabelsTest)
println("----Training-----")
println("F1-Score = " + multiEvaluator.evaluate(predictionsTrain))
println("Accuracy = " + multiMetricsTrain.accuracy)
println("Confusion matrix:\nSpam\tNotSpam\n"+ multiMetricsTrain.confusionMatrix)
println("----Testing-----")
println("F1-Score = " + multiEvaluator.evaluate(predictionsTest))
println("Accuracy = " + multiMetricsTest.accuracy)
println("Confusion matrix:\nSpam\tNotSpam\n"+ multiMetricsTest.confusionMatrix)
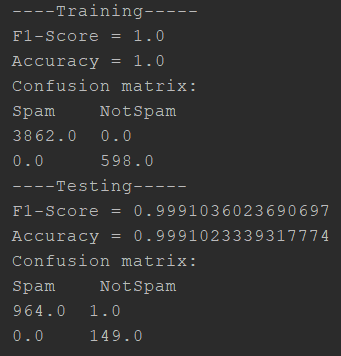
Figure: Raw output of model evaluation
At the time of writing the Spark api did not expose an easy way to print the parameters of the best model with a simple function call, but of course searching on stackoverflow gives us a way. We find out that the best model was the one with vocabulary sizes of 1000 and 20 maximum iterations.
Last note
The performance of our model is spectacular, almost suspicious for data leakage. But we have made sure in the above steps that no data leakage takes place, isolating training and testing phases and data. Training accuracy is 100% and testing accuracy is 99.9%. Our model makes only one mistake in the test set, classifying a spam message as non spam, resulting in an $f_1 score \approx 0.999$. If we didn’t achieve that high performance we would think to apply stemming to the words before weighting them with TF-IDF, but our simple pipeline already solves the problem adequately.
This was a very simple dataset. If you encounter close to perfect test score in your problems, be very suspicious. All models are wrong, some are useful.