Creating a Recommender System with a Graph DB (Neo4j)
This work is based on a project on the Semantic Data Management course I followed in Barcelona in the summer semester 2018-2019 as part of the BDMA Erasmus Mundus Master program.
It was done in collaboration with my lab mate Elena Ouro. Code available on github.
The problem description
The problem is to design and implement a graph database for publishing academic literature. Then, to use an algorithm based on pagerank to suggest reviewers for papers of the database community.
Model design
To start with, we designed the data model of the property graph.
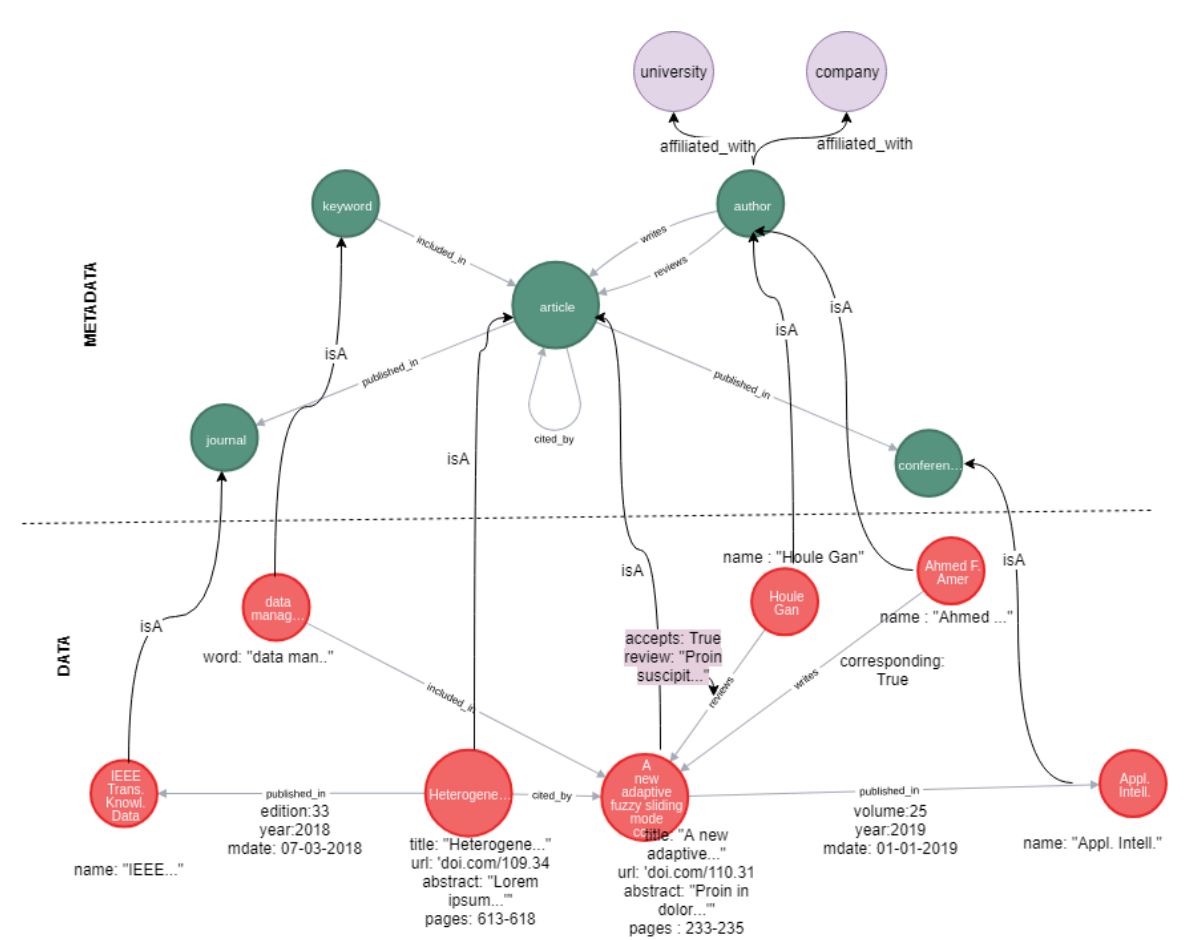
Graph model schema (upper green part) and corresponding metadata of a specific instance. Purple nodes were used to extend the graph.
Data
We got data from dblp and and converted to csv using a [converter we found on github](add link) that transforms the dblp file to a format that is readable by neo4j import.
1. Data wrangling
Data were not ready to be imported after previous step. We had to further enhance and modify the generated CSVs with the following simplified approach:
First author that appears for an article is the corresponding author
Every paper has 3 random reviewers
Abstracts were generated as lorem ipsum… paragraphs using the python module lorem.
We split the research papers in two: a) 10000 that can be cited and b) all the others that cite the first group. An article gives a random number of citations between 1 and 100 to articles in group a. We consider the date on which an article was published to ensure a paper does not cite another one that was published later.
We took keywords from informs.org and added them to the database community keywords mentioned. Then we randomly assigned some of them to all the articles. Since we knew that the existing citations were made in articles of specific conferences, we assigned all these articles at least one keyword of the db community, to obtain results for the recommender.
As no conferences were present in our data, we changed arbitrarily some of the journals to conferences and their volumes to editions.
After this process, we have our CSVs that will be used to create our property graph.
Check the code to prepare the data.
2. Data loading
We imported the data using the neo4j-admin import tool, which I would say is the simpler and fastest (easy to learn and very efficient) way to load batch data into your neo4j graph for the first time. You just have to make sure that file names and headers of the CSVs match your schema and the input format of the import tool and all data will be imported very rapidly.
Check the actual code here.
Querying the graph
1. Find the h-indexes of the authors in your graph
If you have an h-index $n$, it means that you have authored at most $n$ articles with at least $n$ citations.
MATCH (au:author)-[:writes]->(a:article)-[cit:cited_by]->(ac:article)
WITH au.name as author_name, a.title as title, count(*) as num_cites
ORDER BY num_cites desc
WITH author_name, collect(num_cites) as list_num_cites
WITH author_name, [x IN range(1,size(list_num_cites)) where x<=list_num_cites[x-1]| [list_num_cites[x-1],x] ] as h_index_list
RETURN author_name,h_index_list[-1][1] as h_index
ORDER BY h_index desc
2. Find the top 3 most cited papers of each conference.
MATCH (ac:article)<-[cit:cited_by]-(a:article)-[p:published_in]->(c:conference)
WITH c, a, count(*) as cites
ORDER BY c, cites DESC
WITH c, collect([a,cites]) as papers
RETURN c.name as conference_name,
papers[0][0].title as paper1, papers[0][1] as num_cites1,
papers[1][0].title as paper2, papers[1][1] as num_cites2,
papers[2][0].title as paper3, papers[2][1] as num_cites3
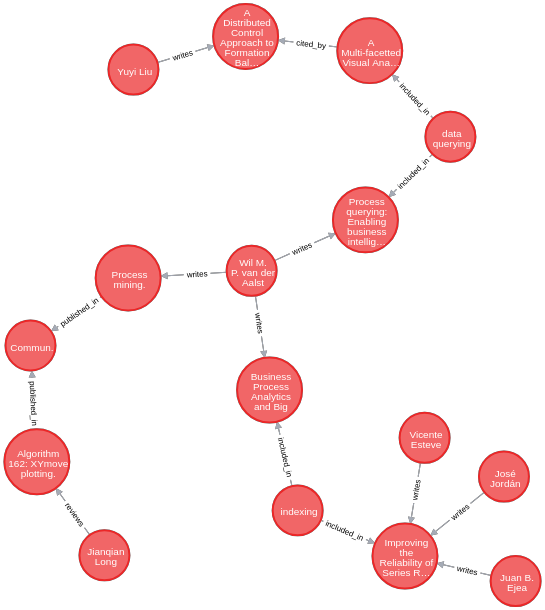
3. Shortest paths between Wil Van der Aalst and 5 other authors
MATCH (start:author{name:'Wil M. P. van der Aalst'})
MATCH (end:author) where end<>start
WITH start, end limit 5
CALL algo.shortestPath.stream(start, end, 'cost')
YIELD nodeId, cost
WITH start, nodeId,cost
return algo.getNodeById(nodeId)
Neo4j shows the following nice visualization of the returned graph.
Building the recommender
The recommender was a step by step implementation, based on the project description. We will identify potential reviewers for the database community.
Step 1. Find/Define DB research communities
// Step 1.1 - Create database community node
create (:community {name:'db'}) // run before next query
// Step 1.2 - Define which keywords related to the database community
match (c:community {name:'db'})
match (kw:keyword)
where kw.word in ['data management', 'indexing', 'data modeling', 'big data', 'data processing', 'data storage' , 'data querying']
merge (kw)-[:related_to]->(c)
Step 2. find the conferences and journals related to the database community.
Assumption: If 90% of the papers published in a conference/journal contain one of the keywords of the database community, we consider that conference/journal as related to that community.
// Step 2 - Find the conferences or journals that relate to the database community (90% of their articles include keywords related to the db community)
match (a:article)-[:published_in]->(c1)
with c1, c1.name as conference, count(*) as num_papers
where num_papers > 0
match (c1)<-[:published_in]-(a:article)<-[:included_in]-(kw:keyword)-[:related_to]->(com:community {name:'db'})
with c1,com,conference, num_papers, count(distinct a.title) as num_papers_db
with c1,com,conference, num_papers, num_papers_db, (1.0*num_papers_db/num_papers) as db_percentage
where db_percentage >=0.9
merge (c1)-[:related_to]->(com)
return conference, num_papers,num_papers_db, db_percentage
Step 3. Next, we want to identify the top papers of these conferences/journals.
Recommending is a ranking problem. We find the papers with the highest page rank provided the number of citations from the papers of the same community (papers in the conferences/journals of the database community). As a result, we would obtain (highlight), say, the top-100 papers of the conferences of the database community.
CALL algo.pageRank.stream(
'match (a:article)-[:published_in]->(c1)-[:related_to]->(com:community) where com.name="db" return id(a) as id',
'match (com1:community)<-[:related_to]-(c1)<-[:published_in]-(a1:article)-[cit:cited_by]->(a2:article)-[:published_in]->(c2)-[:related_to]->(com2:community) where com1.name="db" and com2.name="db" return id(a1) as source, id(a2) as target',{graph:'cypher'})
YIELD nodeId, score
WITH algo.getNodeById(nodeId) AS a,score
ORDER BY score DESC
match (com:community {name:'db'})
merge (a)-[:related_to]->(com)
return a.title, score
limit 100
Step 4. Return recommendations
An author of any of these top-100 papers is automatically considered a potential good match to review database papers. In addition, we want to identify gurus, i.e., very reputated authors that would be able to review for top conferences. We identify gurus as the authors of, at least, two papers among the top-100 identified.
match (au:author)-[:writes]->(:article)-[:related_to]->(com:community {name:'db'})
with au, count(*) as num
with au, au.name as author_name, num as num_influential_papers, case when num >=2 then 'guru' else 'reviewer' end as reviewer_type
merge (au)-[:related_to {type:reviewer_type}]->(com)
return author_name, num_influential_papers, reviewer_type
order by num_influential_papers desc
Ending Note
In this article, we’ve seen
the design of a graph model,
how to wrangle data for importing it to neo4j,
how to perform queries in Cypher
and how to build a simple reviewer recommender based on graphs and pagerank.
Take-home message: Graph Databases are efficient for navigating through relations and make query-writing natural. They are the natural choice for representing connected data, analyzing their interactions and performing Graph Analytics (shortest paths, pagerank, betweeness, etc) on them.